-
产品及解决方案
-
服务


-
产品及解决方案
-
服务


-
云原生产品及应用平台
-
云服务
华邦电子从头界说AI内存:为新一代运算打造高带宽、低延迟解决方案
发布时间:2025-08-28 来历:投稿 责任编纂:admin
跟着高效能运算(HPC)事情负载日趋繁杂,天生式 AI 正加快整合进现代体系,鞭策进步前辈内存解决方案的需求是以日趋增长。为了应答这些快速演进的需求,业界正踊跃成长新一代内存架构,致力在晋升带宽、降低延迟,同时增长电源效能。DRAM、LPDDR 以和利基型内存技能的冲破正从头界说运算效能,而专为 AI 优化的内存方案,则饰演了驱动效率与扩大性的要害脚色。华邦的半定制化超高带宽元件 (CUBE) 内存便是此进展的代表,提供高带宽、低功耗的解决方案,撑持 AI 驱动的事情负载。本文将切磋内存技能的最新冲破、AI 运用日趋增加的影响力,以和华邦怎样透过计谋性结构相应市场不停变化的需求。
进步前辈内存架构与效能扩大
内存技能正迅速演进,以满意 AI、AIoT 与 5G 体系对于效能的严苛要求。财产正迎来史无前例的架构改造,DDR5 与 HBM3E 的广泛运用将成为新趋向,这些技能可同时提供更高带宽与更佳的能源效率。DDR5 的单脚位数据速度最高可达 6.4 Gbps,每一模块可达 51.2 GB/s,效能险些为 DDR4 的两倍,且事情电压由 1.2V 降至 1.1V,进一步晋升功耗效率。HBM3E 则将带宽推升至每一仓库逾 1.2 TB/s,为 AI 年夜型练习模子提供抱负的效能。然而,其高功耗特征使其不合适用在挪动装备与边沿端部署。

跟着 LPDDR6 估计于 2026 年冲破 150 GB/s 的带宽,低功耗内存正朝向更高的传输效率与能源效益迈进,以应答 AI 智能型手机与嵌入式 AI 加快器所面对的挑战。华邦正于研发小容量的 DDR5 及 LPDDR4 解决方案,以便对于功耗要求运用举行优化。同时,华邦推出了 CUBE 内存,旨于实现跨越 1 TB/s 的带宽并降低热耗散。
CUBE 的将来容量预期可扩大至每一组 8GB,甚至更高。例如,采用单一光罩区(reticle size)制程的 4Hi WoW 仓库架构,可实现逾 70GB 的容量与 40TB/s 的带宽,使 CUBE 成为 AI 边沿运算范畴中,相较传统内存架构更具上风的替换方案。
此外,CUBE 的子系列 CUBE-Lite 提供 8-16GB/s 的带宽(相称在 LPDDR4x x16/x32),其运作功耗仅为 LPDDR4x 的 30%。于不搭载 LPDDR4 PHY 的环境下,SoC 仅需整合 CUBE-Lite 节制器,便可告竣相称在 LPDDR4x 满速的带宽体现,不仅可节省高额的 PHY 授权用度,更能采用 28nm 甚至 40nm 的成熟制程节点,告竣原先仅能于 12nm 工艺下实现的效能程度。
此架构尤其合用在整合NPU 的 AI-SoC、AI-MCU,可驱动具有电池供电需求的 TinyML 终端装配。搭配 Micro Linux 操作体系 与 AI 模子履行,可运用在 IP 开麦拉、AI 眼镜、穿着式装备等低功耗 AI-ISP 终端场景,有用告竣体系功耗优化与芯单方面积缩减的两重效益。
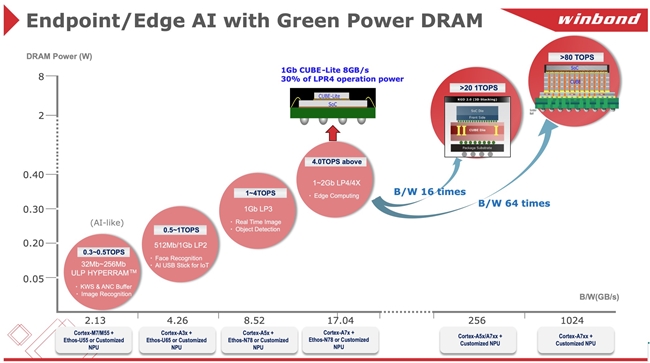
天生式AI部署下的内存瓶颈
天生式 AI 模子的指数级增加将带来史无前例的内存带宽与延迟挑战。尤其是基在 Transformer 架构的 AI 事情负载,对于运算吞吐量与高速数据存取能力有极高需求。
以 LLamA2 7B 为例,于 INT8 模式下部署至少需要 7GB 的内存,即便转为 INT4 模式仍需 3.5GB,凸显今朝挪动装备内存容量的限定。现阶段利用 LPDDR5(带宽 68 GB/s)的 AI 智能型手机,已经面对较着瓶颈,市场急需 LPDDR6 的进一步成长。然而,于 LPDDR6 商用化以前,仍需有过渡性解决方案来弥补带宽缺口。
从体系层面来看,呆板人、主动驾驶汽车与智能传感器等 AI 边沿运用也对于功耗与散热提出更严苛的挑战。只管 JEDEC 尺度正朝 DDR6 与 HBM4 演进,以晋升带宽使用率,华邦的 CUBE 内存作为一种半定制化架构,则提供切合 AI SoC 要求的高扩大性与高效能替换方案。CUBE 联合了 HBM 级别带宽与低在 10W 的功耗,是边沿 AI 推理使命的抱负选择。
散热与能源效率的两重挑战
将年夜型 AI 模子部署至终端装备,将面对显著的散热与能源效率挑战。AI 事情负载自己即需年夜量能耗,所孕育发生的高热轻易影响体系不变性与效能体现。
•装配端内存扩充:
为削减对于云端 AI 处置惩罚的依靠并降低延迟,步履装配需整合更高容量的内存。然而,传统 DRAM 的扩大已经靠近物理极限,将来须透过混淆式架构,整合高带宽与低功耗内存以冲破瓶颈。
•HBM3E与CUBE的比力:
只管 HBM3E 可实现极高的数据传输速度,但其单仓库功耗跨越 30W,其实不合用在挪动边沿运用。华邦的 CUBE 则可作为替换型末了层快取 (Last Level Cache, LLC),有用降低对于芯片内 SRAM 的依靠,同时维持高速数据存取能力。跟着逻辑制程迈入次 7nm 时代,SRAM 面对更严峻的缩放瓶颈,凸显新一代快取解决方案的火急需求。
•散热优化计谋:
AI 处置惩罚可能致使单一芯片孕育发生跨越 15W 的热负载,是以,怎样有用分配功耗与举行热治理成为要害。华邦透过 CUBE 采用的 TSV(Through Silicon Via, 硅穿孔)封装技能,并优化内存的刷新周期,协助于小型扮装置中实现 AI 履行的最好能效。
DDR5与DDR6:推升AI运算效能的催化剂
DDR5 与 DDR6 的演进标记着 AI 体系架构的庞大迁移转变点,带来更高的内存带宽、更低延迟以和更佳的扩大性。
DDR5 采用 8 组 Bank Group 架构与芯片内建的 ECC(Error-Correcting Code , 过错批改码),提供优秀的数据完备性与效能,很是合适用在 AI 强化的条记本电脑与高效能 PC。其单模块的最年夜传输率达 51.2 GB/s,能撑持及时推理、多使命处置惩罚与高速数据运算需求。
DDR6 今朝仍于研发阶段,预期将实现跨越 200 GB/s 的模块带宽,功耗降低约 20%,并针对于 AI 加快器举行优化设计,进一步拓展 AI 运算的极限。
华邦于AI内存范畴的计谋带领力
华邦踊跃鞭策专为 AI 事情负载与嵌入式处置惩罚运用所设计的内存架构立异,其市场计谋重点包括:
· CUBE作为AI优化内存:
透过 TSV(穿硅互连)技能,整合高带宽与低功耗特征,CUBE 是步履与边沿 AI SoC 的抱负内存解决方案。
· 与OSAT互助伙伴协同立异:
华邦与外包半导体封装与测试(OSAT)伙伴紧密亲密互助,鞭策与下一代 AI 硬件的深度整合,优化内存封装效率并降低体系延迟。
· 面向将来的内存立异蓝图:
华邦专注在 AI 专用内存解决方案、专属高速缓存设计,以和优化 LPDDR 架构,致力在撑持高效能运算、呆板人与及时 AI 处置惩罚等将来运用。

结语
AI 驱动的事情负载、效能扩大的挑战,以和对于低功耗内存解决方案的火急需求,正配合鞭策内存市场的深度转型。天生式 AI 的迅猛成长,加快了对于低延迟、高带宽内存架构的渴求,进一步促使内存与半定制化内存技能连续立异。
华邦依附其于 CUBE 内存和 DDR5/LPDDR 系列技能上的领先上风,已经成为新一代 AI 运算的主要推手。跟着 AI 模子日趋繁杂,市场对于兼具高效能与能源效率的内存架构需求将越发火急。华邦对于技能立异的持久承诺,让其连续站稳 AI 内存进化的前沿,实现高效能运算与可连续扩大性之间的最好均衡。
###
关在华邦电子
华邦电子为全世界半导体存储解决方案带领厂商,重要营业包罗产物设计、技能研发、晶圆制造、营销和售后办事,致力在提供客户全方位的利基型内存解决方案。华邦电子产物包罗利基型动态随机存取内存、步履内存、编码型闪存及TrustME®安全闪存,广泛运用于通信、消费性电子、工业用以和车用电子、计较机周边等范畴。华邦电子总部位在台湾中部科学园区,于台中与高雄设有两座12寸晶圆厂,将来将连续导入自行开发的制程技能,为互助伙伴提供高质量的内存产物。此外,华邦于中国年夜陆和中国香港地域、美国、日本、以色列、德国等地均设有子公司,卖力营销营业并为客户提供当地撑持办事。
Winbond 为华邦电子株式会社(Winbond Electronics Corporation)的注册牌号,本文说起的其他牌号和版权为其原有人所有。
-XK星空·(体育中国)官方网站
版权所有2016-2025 XK星空·(体育中国)官方网站数码集团股份有限公司,保留一切权利。





